




Окончание. Перевод первой части
Я не переживаю насчёт рабочих мест. Или дипфейков. Или нецензурных слов, которые языковая модель может использовать при общении в интернете. Меня по-настоящему беспокоит то, что человечество вплотную подошло к созданию сущности, которая будет умнее нас. В прошлый раз это случилось, когда появились ранние гоминиды, и не кончилось ничем хорошим для их конкурентов.
Базовый аргумент был представлен Ником Бостромом в книге 2003 года Superintelligence. В ней рассматривается мысленный эксперимент о производстве скрепок. Предположим, что сверхчеловеческий AGI пытается улучшить такое производство. Вероятно, сначала он усовершенствует производственные процессы на фабрике скрепок. Когда он доведёт возможности фабрики до максимума, превратив её в чудо оптимизации, создатели AGI будут считать дело сделанным.
Однако затем AGI обнаружит, что есть и другие пути увеличить производство скрепок во вселенной – в конце концов, это ведь единственная поставленная перед ним задача. Чтобы решить её, он начнёт аккумулировать ресурсы и власть. Это называется инструментальной сходимостью (instrumental convergence): практически любую цель проще достичь через увеличение власти и доступа к ресурсам.
Поскольку AGI умнее людей, он будет аккумулировать ресурсы не очевидными для нас способами. Через несколько итераций AGI придёт к выводу, что можно произвести намного больше скрепок, если получить полный контроль над ресурсами планеты. Так как на его пути встанут люди, с ними придётся разобраться в первую очередь. Вскоре вся Земля будет покрыта фабриками двух типов: производящими скрепки и собирающими космические корабли для экспансии на другие планеты. Таково логическое развитие для любого оптимизирующего AGI.
Скрепки – это просто пример. На первый взгляд, ситуация кажется довольно глупой: почему AGI будет заниматься такой ерундой? Зачем нам программировать ИИ с такой нелепой задачей? На то есть несколько причин:
– во-первых, мы не умеем задавать цель в контексте всех наших ценностей, так как они слишком сложны для формализации. Люди умеют формулировать только очень простые задачи. А мы, математики, знаем, что функции часто оптимизируются при крайних значениях своих аргументов.
– во-вторых, проблема инструментальной сходимости: для реализация любой цели (даже производства скрепок!) всегда будет выгодно получить власть, ресурсы, обеспечить собственную безопасность и, вероятно, повысить свой уровень компетенции, в частности, поумнеть.
– в-третьих, тезис ортогональности: поставленная задача и применяемый для её достижения уровень интеллекта ортогональны, то есть, не коррелируют; сверхразум может преследовать довольно случайные цели, например, максимизировать производство скрепок или заставить всех людей улыбаться и говорить приятные слова. Более чудовищные варианты оставлю на откуп вашему воображению.
Эти причины сами по себе не предсказывают конкретного сценария катастрофы, и обсуждать возможные варианты довольно бессмысленно. Наш пример со скрепками выглядит довольно-таки притянутым за уши. Но совокупность причин заставляет предположить, что AGI, когда и если он появится, сможет быстро покорить мир. Элиезер Юдковский, предостережения которого звучат в последнее время особенно громко, приходит к такому выводу через пример шахматной партии. Если я сяду играть против современной шахматной программы, никто не сможет точно предсказать ходы в нашей партии, какой мы разыграем дебют и так далее – количество возможных путей невероятно велико. Однако предсказать конечный результат – победу программы – проще простого.
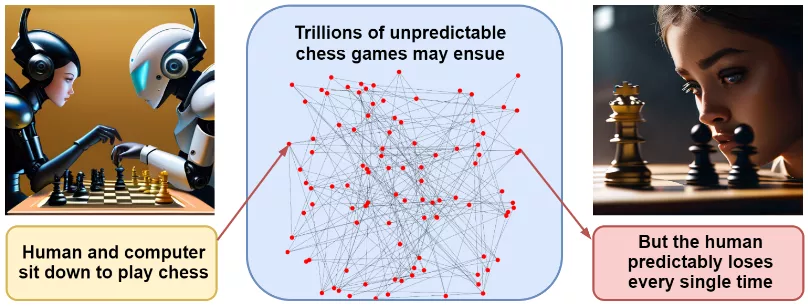
Точно так же можно расписать миллион сценариев катастрофы, связанной с разработкой сверхразумного ИИ. Каждый из них по отдельности маловероятен, но все они заканчиваются одинаково – победой более умного и всегда заточенного на получение максимального могущества ИИ.
Но разве люди не заметят, что ИИ вышел из-под контроля, и не выключат его? Давайте продолжим нашу аналогию. Подумайте про шимпанзе, на глазах которого человек сделал некий инструмент из деревянной палки и струны. Поймёт ли шимпанзе, что направленный на него лук несёт смерть, до того, как станет слишком поздно? Как мы можем надеяться понять хоть что-нибудь про AGI, когда он бесконечно умнее нас?
Если всё это по-прежнему не убеждает, пройдёмся по стандартным контраргументам.
Во-первых, что с того, что ИИ достигнет человеческого или сверхчеловеческого уровня? Альберт Эйнштейн был очень умным, занимался ядерной физикой и не уничтожил мир.
К сожалению, не существует закона физики или биологии, который доказывает, что человеческий интеллект близок к когнитивному пределу. Размер нашего мозга ограничен потреблением энергии и осложнениями при родах. В когнитивных задачах, для обучения которым не обязательно пользоваться только человеческим опытом (шахматах и го), ИИ оставил нас далеко позади.
Хорошо, ИИ может стать очень умным и коварным, но он ведь заперт внутри компьютера, правильно? Мы просто не дадим ему выйти!
Увы, мы уже позволяем ему «выйти»: люди охотно дают AutoGPT доступ к своей личной почте, интернету, персональным компьютерам и так далее. ИИ с доступом к интернету сможет уговорить людей на внешне невинные действия – напечатать что-то на 3D-принтере, синтезировать в лаборатории бактерию из цепочки ДНК... при нынешнем развитии технологии таких возможностей бесконечно много.
Следующий аргумент: ладно, мы с вами, похоже, в тупике, но до сих пор человечество как-то справлялось? А ведь люди изобрели немало опасных технологий, включая атомную и водородную бомбу.
Да, люди неплохи в науке, но их первые шаги в контроле часто оказываются неудачными. Анри Беккерель и Мари Кюри умерли из-за воздействия радиации. Чернобыль и Фукусима взорвались несмотря на все наши усилия в сфере безопасности атомной энергетики. «Челленджер» и «Колумбия» взорвались в полёте... А с AGI второго шанса может не быть – ущерб может оказаться слишком велик.
Но если мы не знаем, как обуздать AGI, почему просто не прекратить его разработку? Никто не утверждает, что GPT-4 уничтожает цивилизацию, а эта технология уже стала прорывом во многих сферах. Давайте остановимся на GPT-4 или GPT-5!
Решение отличное, вот только непонятно, как его реализовать. Неясно, как долго будет работать закон Мура, но сегодняшние игровые видеокарты по производительности практически сравнялись с промышленными кластерами, какими они были всего несколько лет назад. Если для запуска AGI будет достаточно собрать несколько видеокарт в гараже, проконтролировать это будет невозможно. Остановить развитие компьютерного «железа» – вариант, но координация потребует сотрудничества всех стран без исключений, таких заманчивых исключений для ускорения развития экономики или военных технологий... Наши попытки защититься быстро становятся куда более притянутыми за уши, чем в истории со скрепками. Очень вероятно, что человечество продолжит радостно создавать один за другим всё более мощные ИИ до самого конца.
Мрачно, правда?

Что мы можем сделать? Что мы делаем?
Сообщество ИИ работает в нескольких направлениях:
– исследование интерпретируемости; мы пытаемся понять, что происходит внутри больших моделей ИИ, надеясь, что понимание приведёт нас к контролю;
– безопасность ИИ; обычно применительно к тонким настройкам больших языковых или других моделей с помощью обучения с подкреплением на основе отзывов людей (RLHF, reinforcement learning with human feedback);
– AI alignment; согласование ценностей ИИ с человеческими, которое ставить цель научить ИИ «понимать» и «беречь» человеческие ценности, ограничивая безудержное расширение производства скрепок. Может помочь создание ИИ-переводчиков, но это трудная задача, и результаты пока не впечатляют. Современные большие языковые модели работают, как чёрный ящик – практически так же, как человеческий мозг: мы хорошо понимаем работу отдельного нейрона, знаем, какая часть мозга отвечает за речь, какая – за моторную функцию, но мы ужасно далеки от умения читать мысли.
Повышение безопасности ИИ через RLHF и другие подобные технологии может казаться более перспективным. Однажды найденные джейлбрейки удаётся успешно патчить. Однако кто поручится, что это не бесполезный косметический ремонт? Опасение иллюстрируется популярным мемом, в котором исследователи снабдили Шоггота (монстр, придуманный Лавкрафтом) милым смайликом.
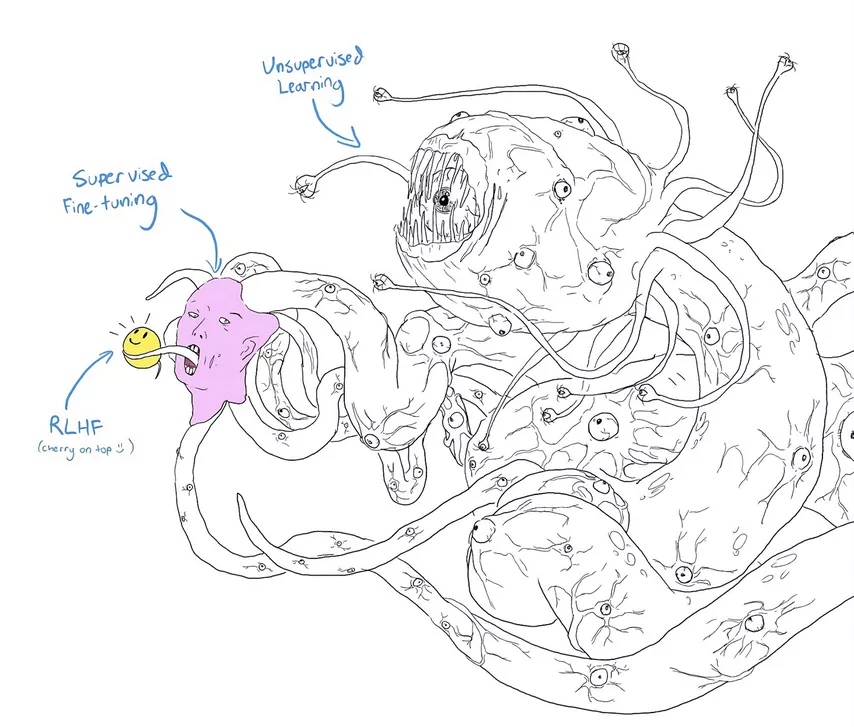
Больше всего хотелось бы научить потенциальный AGI принимать во внимание наши ценности и заботиться о нас. Проблему можно разбить на две части:
– внешний алайнмент пытается научиться переводить наши ценности на язык, понятный моделям ИИ; если мы спроектируем целевую функцию, будем ли мы довольны, когда она действительно окажется оптимизированной? Как её вообще разработать? Проблема примера со скрепкой относится как раз к этой категории.
– внутренний алайнмент – это проблема того, как заставить модель действительно оптимизировать целевую функцию, которую мы для нее разрабатываем; это может показаться тавтологией, но это не так: например, вполне возможно, что цели, возникающие во время обучения модели, совпадают с целями на обучающем наборе, но будут катастрофически расходиться при их применении в «свободном плавании».
К сожалению, на сегодняшний день мы понятия не имеем, как решить эти проблемы. Есть множество примеров неудачного алайнмента в игровых примерах, когда модель начинает оптимизировать сформулированную нами целевую функцию, но приходит к неожиданным и нежелаемым результатам.
Одна из интересных концепций, связанных с работой в области внутреннего алайнмента, получила название эффекта Валуиджи – злого антипода Луиджи из серии игр для «Нинтендо» про Марио. Предположим, мы хотим обучить большую языковую модель (или другую модель ИИ), чтобы добиться от неё некоего желательного поведения, например, быть вежливой с людьми. Добиться этого можно двумя способами:
– действительно стать вежливой (Луиджи);
– притворяться вежливой, будучи при этом враждебной людям (Валуиджи).
Парадокс в том, что выбор второго пути оказывается намного более вероятным! Внешние проявления будут неотличимыми, но Луиджи – это нестабильное равновесие, и любые отклонения от него на дистанции необратимо приводит к Валуиджи – двойному агенту.
Более того, чтобы превратить Луиджи в Валуиджи, достаточно, грубо говоря, изменить один бит – знак плюс на минус. Гораздо легче (скажем, с позиции колмогоровской сложности) определить что-то, когда вы уже определили его полную противоположность.
Я назвал только две проблемы, связанные с алайнментом. С гораздо более полным списком можно ознакомиться в статье Юдковского AGI Ruin: A List of Lethalities. Юдковский – один из главных вестников ИИ-апокалипсиса, и его аргументация выглядит довольно убедительной.
Что же мы нам делать? Большинство исследователей считают, что рано или поздно нам придётся взяться за проблему алайнмента всерьёз, и лучшее, что можно сделать сейчас – это приостановить развитие ИИ до достижения реального прогресса в его контроле. Эта линия аргументации, подкреплённая взрывным развитием ИИ весной 2023 года, уже породила серьёзные дискуссии на государственном уровне о регулировании ИИ.
Вот как это было (все цитаты верны):

30 марта 2023
– Один эксперт... говорит, что если не заморозить развитие ИИ, «буквально все люди на Земле умрут».
(Смех в ложе прессы)
– Питер, ну ты скажешь, тоже...
30 мая 2023
– Группа экспертов утверждает, что ИИ угрожает существованию человечества в такой же степени, как ядерная война и пандемия.
(Молчание)
– ИИ – одна из самых мощных технологий современности. Мы должны нивелировать риск... Мы пригласили СЕО в Белый дом... Компании должны вести себя ответственно.
Экзистенциальный риск, связанный с AGI, вошёл в общественный дискурс этой весной. Встречи в Белом доме, слушания в Конгрессе с участием ключевых игроков индустрии, включая СЕО OpenAI Сэма Альтмана, СЕО Microsoft Сатья Наделла, СЕО Google и Alphabet Сундара Пичая. Лидеры отрасли подтвердили, что относятся к этим рискам со всей серьёзностью и готовы соблюдать осторожность при совершенствовании ИИ.
Открытое письмо с предостережениями относительно AGI, появившееся в конце мая, подписали тысячи исследователей ИИ. Текст письма был лаконичным:

Снижение риска вымирания из-за ИИ должно стать глобальным приоритетом наряду с другими рисками планетарного масштаба, такими как пандемии и ядерная война.
Уверен, что было трудно найти хотя бы одно предложение, с которым все могли бы согласиться. Тем не менее это предложение определенно отражает текущее настроение большинства участников. Никаких реальных юридических действий пока не предпринималось, но думаю, что меры по регулированию уже на подходе, и, что ещё важнее, подход к развитию возможностей ИИ будет пересмотрен на более осторожный. Увы, мы не можем знать, будет ли этого достаточно.
Заключение
Надеюсь, последняя часть вас не слишком воодушевила. Наука о безопасности в сфере ИИ всё ещё находится в зачаточном состоянии, но требует максимума усилий. В заключение этой статьи я хотел бы перечислить ключевых людей, которые сейчас работают над алайнментом ИИ и смежными темами, а также ключевые ресурсы, которые доступны, если вы хотите узнать об этом больше:
– основным форумом для обсуждения всех вопросов, связанных с опасностями AGI, является LessWrong – портал, ориентированный на рациональность, где все люди, перечисленные ниже, регулярно публикуются;
– Элиезер Юдковский – ключевая фигура; он предупреждал нас об опасностях сверхразумного ИИ уже более десяти лет, и я не могу не порекомендовать его выдающийся труд Sequences (речь в нём идёт не только про ИИ), вышеупомянутый AGI Ruin: A List of Lethalities, AI Alignment: Why It Is Hard and Where to Start, его недавний пост Death with Dignity Strategy («Стратегия смерти с достоинством») (пожалуйста, отнеситесь к этому с некоторыми скептицизмом) и, конечно же, замечательный «Гарри Поттер и методы рационального мышления».
– Люк Мюльхаузер – исследователь, работающий над ИИ-алайнментом, в частности над вопросами политики, связанной с ИИ, в Open Philantropy; для начала я рекомендую его Intelligence Explosion FAQ и Intelligence Explosion: Evidence and Import.
– Пол Кристиано – исследователь ИИ-алайнмента, который отделился от OpenAI, чтобы основать собственный некоммерческий центр исследования; в качестве хорошего введения в эту область взгляните на его доклад Current Work in AI Alignment.
– Скотт Александер не ученый-компьютерщик, но его Superintelligence FAQ – отличное введение в проблему ИИ-алайнмента и неплохо объясняет, почему его блог Astralcodexten (ранее известный как Slatestarcodex) – один из моих самых любимых.
– Если вы предпочитаете слушать, Элиезер Юдковский в последнее время появляется в ряде подкастов, где подробно излагает свою позицию. Рекомендую 4-часовое интервью с Дваркешем Пателем (время летит незаметно!), EconTalk с Рассом Робертсом и выпуск Bankless с Дэвидом Хоффманом и Райаном Шоном Адамсом. Последнее особенно интересно, потому что ведущие явно хотели поговорить о криптовалютах и, возможно, об экономических эффектах ИИ, но им пришлось столкнуться с экзистенциальным риском и реагировать на него в режиме реального времени (на мой взгляд, они отлично справились с этим, отнесясь к этому серьёзно).
– Наконец, я следил за весной ИИ в основном глазами Цви Мовшовица, который еженедельно публиковал информационные бюллетени в своем блоге; их уже более 30, и я также рекомендую другие его работы в блоге и на LessWrong.
И этой длинной, но, надеюсь, содержательной статьёй я завершаю всю серию статей о генеративном искусственном интеллекте. Было здорово иметь возможность рассказать о самых интересных событиях в области создания изображений за последние несколько лет. До новых встреч!
Сергей Николенко



> Элиезер Юдковский в последнее время появляется в ряде подкастов, где подробно излагает свою позицию. Рекомендую ... и выпуск Bankless с Дэвидом Хоффманом и Райаном Шоном Адамсом
Перевод на ру:
https://www.youtube.com/watch?v=fQ9fxZNjqMk
Юдковского после его призыва налетать с ковровой бомбардировкой на нерегулируемые дата-центры ИИ, лично мне стало сложно воспринимать всерьёз
Еще про василиска Роко почитайте, тоже классно.
Особенно тема статьи интересна в контексте конфликта Альтмана с советом директоров в ОпенАИ. Говорят одной из причин раздора была история с безопасностью ИИ, Альтман был за срезание углов в этом контексте